radis.lbl.factory module¶
Contains the SpectrumFactory class, which is
the core of the RADIS Line-by-Line module.
Examples
Calculate a CO Spectrum, fetching the lines from HITRAN
# This is how you get a spectrum (see spectrum.py for front-end functions
# that do just that)
sf = SpectrumFactory(2125, 2249.9,
molecule='CO',
isotope=1,
cutoff=1e-30, # for faster calculations. See
# `plot_linestrength_hist` for more details
**kwargs)
sf.fetch_databank() # auto download from HITRAN
s = sf.eq_spectrum(Tgas=300)
s.plot('abscoeff') # opacity
# Here we get some extra informations:
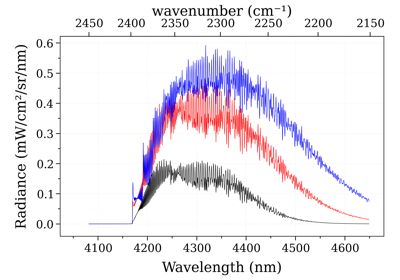
s.plot('radiance', wunit='nm',
Iunit='µW/cm2/sr/nm', # Iunit is arbitrary. Use whatever makes sense
show_points=True) # show_points to have an idea of the resolution
See radis.test.lbl.test_factory for more examples
Routine Listing¶
(the following sections are marked on the slider bar in the Spyder IDE with the # XXX symbol)
PUBLIC METHODS
eq_spectrum()>>> calc equilibrium spectrumnon_eq_spectrum()>>> calc non equilibrium spectrumoptically_thin_power()>>> get total power (equilibrium or non eq)
Most methods are written in inherited class with the following inheritance scheme:
DatabankLoader > BaseFactory >
BroadenFactory > BandFactory >
SpectrumFactory

Notes
Debugging:
Remember one can access all locals variable in a function either by running
%debug after a crash in IPython. Or by adding the line globals().update(locals())
at any point
Performance:
Fast version: iterate over chunks of dataframe Note that we can’t use the full dataframe because it’s too big and takes too much memory See Performance for more details.
for Developers:
To implement new database formats, see the databases parsers in cdsd.py / hitran.py, and the partition function interpolators / calculators methods of SpectrumFactory:
_build_partition_function_calculator()and_build_partition_function_interpolator()
- class SpectrumFactory(wmin=None, wmax=None, wunit=cm - 1, wavenum_min=None, wavenum_max=None, wavelength_min=None, wavelength_max=None, Tref=296, pressure=1.01325, mole_fraction=1, path_length=1, wstep=0.01, isotope='all', medium='air', truncation=50, neighbour_lines=0, pseudo_continuum_threshold=0, self_absorption=True, chunksize=None, optimization='simple', folding_thresh=1e-06, zero_padding=-1, broadening_method='voigt_poly', cutoff=0, parsum_mode='full summation', verbose=True, warnings=True, species=None, save_memory=False, export_populations=None, export_lines=False, gpu_backend=None, diluent=None, lbfunc=None, potential_lowering=None, pfsource='default', **kwargs)[source]¶
Bases:
BandFactoryA class to put together all functions related to loading CDSD and HITRAN databases, calculating the broadenings, and summing over all the lines.
- Parameters:
wmin, wmax (
floatorQuantity) – a hybrid parameter which can stand for minimum (maximum) wavenumber or minimum (maximum) wavelength depending upon the unit accompanying it. If dimensionless,wunitis considered as the accompanying unit.wunit (
'nm','cm-1') – the unit accompanying wmin and wmax. Can only be passed with wmin and wmax. Default is"cm-1".wavenum_min, wavenum_max (
float(cm^-1)orQuantity) – minimum (maximum) wavenumber to be processed in \(cm^{-1}\). use astropy.units to specify arbitrary inverse-length units.wavelength_min, wavelength_max (
float(nm)orQuantity) – minimum (maximum) wavelength to be processed in \(nm\). This wavelength can be in'air'or'vacuum'depending on the value of the parametermedium=. use astropy.units to specify arbitrary length units.pressure (
float(bar)orQuantity) – partial pressure of gas in bar. Default1.01325(1 atm). use astropy.units to specify arbitrary pressure units. For example,1013.25 * u.mbar.mole_fraction (
float[ 0 - 1]) – species mole fraction. Default1. Note that the rest of the gas is considered to be air for collisional broadening.path_length (
float(cm)orQuantity) – path length in cm. Default1. use astropy.units to specify arbitrary length units.species (
int,str, orNone) –- For molecules:
molecule id (HITRAN format) or name. If
None, the molecule can be inferred from the database files being loaded. See the list of supported molecules inMOLECULES_LIST_EQUILIBRIUMandMOLECULES_LIST_NONEQUILIBRIUM.- For atoms:
The positive or neutral atomic species (negative ions aren’t supported). It may be given in spectroscopic notation or any form that can be converted by
to_conventional_name()
Default
None.isotope (
int,list,strof the form'1,2', or'all') – isotope idFor molecules, this is the isotopologue ID (sorted by relative density: (eg: 1: CO2-626, 2: CO2-636 for CO2) - see [HITRAN-2020] documentation for isotope list for all species.
For atoms, use the isotope number of the isotope (the total number of protons and neutrons in the nucleus) - use 0 to select rows where the isotope is unspecified, in which case the standard atomic weight from the
periodictablemodule is used when mass is required.If
'all', all isotopes in database are used (this may result in larger computation times!).Default
'all'medium (
'air','vacuum') – propagating medium when giving inputs with'wavenum_min','wavenum_max'. Does not change anything when giving inputs in wavenumber. Default'air'diluent (
strordictionary) – can be a string of a single diluent or a dictionary containing diluent name as key and its mole_fraction as value.If left unspecified, it defaults to
'air'for molecules and atomic hydrogen ‘H’ for atoms.For free electrons, use the symbol ‘e-’. Currently, only H, H2, H2, and e- are supported for atoms - any other diluents have no effect besides diluting the mole fractions of the other constituents.
- Other Parameters:
Tref (K) – Reference temperature for calculations (linestrength temperature correction). HITRAN database uses 296 Kelvin. Default 296 K
self_absorption (boolean) – Compute self absorption. If
False, spectra are optically thin. DefaultTrue.truncation (float (\(cm^{-1}\))) – Half-width over which to compute the lineshape, i.e. lines are truncated on each side after
truncation(\(cm^{-1}\)) from the line center. IfNone, use no truncation (lineshapes spread on the full spectral range). Default is50\(cm^{-1}\)Note
Large values (>
50) can induce a performance drop (computation of lineshape typically scale as \(~truncation ^2\) ). The default50was chosen to maintain a good accuracy, and still exhibit the sub-Lorentzian behavior of most lines far (few hundreds \(cm^{-1}\)) from the line center.neighbour_lines (float (\(cm^{-1}\))) – The calculated spectral range is increased (by
neighbour_linescm-1 on each side) to take into account overlaps from out-of-range lines. Default is0\(cm^{-1}\).wstep (float (cm-1) or
'auto') – Resolution of wavenumber grid. Default0.01cm-1. If'auto', it is ensured that there are slightly more points for each linewidth than the value of"GRIDPOINTS_PER_LINEWIDTH_WARN_THRESHOLD"inradis.config(~/radis.json)Note
wstep = ‘auto’ is optimized for performances while ensuring accuracy, but is still experimental in 0.9.30. Feedback welcome!
cutoff (float (~ unit of Linestrength: cm-1/(#.cm-2))) – discard linestrengths that are lower that this, to reduce calculation times.
1e-27is what is generally used to generate databases such as CDSD. If0, no cutoff. Default1e-27.parsum_mode (‘full summation’, ‘tabulation’) – how to compute partition functions, at nonequilibrium or when partition function are not already tabulated.
'full summation': sums over all (potentially millions) of rovibrational levels.'tabulation': builds an on-the-fly tabulation of rovibrational levels (500 - 4000x faster and usually accurate within 0.1%). Defaultfull summation'Note
parsum_mode= ‘tabulation’ is new in 0.9.30, and makes nonequilibrium calculations of small spectra extremely fast. Will become the default after 0.9.31.
pseudo_continuum_threshold (float) – if not
0, first calculate a rough approximation of the spectrum, then moves all lines whose linestrength intensity is less than this threshold of the maximum in a semi-continuum. Values above 0.01 can yield significant errors, mostly in highly populated areas. 80% of the lines can typically be moved in a continuum, resulting in 5 times faster spectra. If0, no semi-continuum is used. Default0.save_memory (boolean) – if
True, removes databases calculated by intermediate functions (for instance, delete the full database once the linestrength cutoff criteria was applied). This saves some memory but requires to reload the database and recalculate the linestrength for each new parameter. DefaultFalse.export_populations (
'vib','rovib',None) – if not None, store populations in Spectrum. Either store vibrational populations (‘vib’) or rovibrational populations (‘rovib’). DefaultNoneexport_lines (boolean) – if
True, saves details of all calculated lines in Spectrum. This is necessary to later useline_survey(), but can take some space. DefaultFalse.chunksize (int, or
None) – Splits the lines database in several chunks during calculation, else the multiplication of lines over all spectral range takes too much memory and slows the system down. Chunksize let you change the default chunk size. IfNone, all lines are processed directly. Usually faster but can create memory problems. DefaultNonefolding_thresh (float) – Folding is a correction procedure that is applied when the lineshape is calculated with the
fftbroadening method and the linewidth is comparable towstep, that prevents sinc(v) modulation of the lineshape. Folding continues until the lineshape intensity is belowfolding_threshold. Setting to 1 or higher effectively disables folding correction.Range: 0.0 < folding_thresh <= 1.0 Default: 1e-6
zero_padding (int) – Zero padding is used in conjunction with the
fftbroadening method to prevent circular convolution at the cost of performance. When set to -1, padding is set equal to the spectrum length, which guarantees a linear convolution.Range: 0 <= zero_padding <= len(w), or zero_padding = -1 Default: -1
broadening_method (
"voigt_poly","convolve","fft") – Available methods:"voigt_poly": polynomial approximation of a Voigt profile.This is the fastest method in most cases (default).
"convolve": independent calculation of Doppler (Gaussian) andcollisional broadening (Lorentzian), then convolution in real space. This is slower but is an exact definition of a Voigt and can be used as a reference for comparison with other methods.
"fft": fast Fourier transform convolution.Only available with
optimization="simple"oroptimization="min-RMS". Because LDM convolves all lines at once, this method is often faster than real-space convolutions on large arrays ("voigt_poly","convolve").
This SpectrumFactory parameter can be manually adjusted a posteriori with:
sf = SpectrumFactory(...) sf.params.broadening_method = 'voigt_poly'
By default,
optimization="simple"andbroadening_method="voigt_poly".optimization (
"simple","min-RMS",None) – If either"simple"or"min-RMS"LDM optimization for lineshape calculation is used:"min-RMS": weights optimized by analytical minimization of the RMS-error (See: [Spectral-Synthesis-Algorithm])"simple": weights equal to their relative position in the grid
If
None, no lineshape interpolation is performed and the lineshape of all lines is calculated.Refer to [Spectral-Synthesis-Algorithm] for more explanation on the LDM method for lineshape interpolation.
By default,
optimization="simple"andbroadening_method="voigt_poly".warnings (bool, or one of
['warn', 'error', 'ignore'], dict) – If one of['warn', 'error', 'ignore'], set the default behaviour for all warnings. Can also be a dictionary to set specific warnings only. Example:warnings = {'MissingSelfBroadeningWarning':'ignore', 'NegativeEnergiesWarning':'ignore', 'HighTemperatureWarning':'ignore'}
See
default_warning_statusfor more information.verbose (boolean, or int) – If
False, stays quiet. IfTrue, tells what is going on. If>=2, gives more detailed messages (for instance, details of calculation times). DefaultTrue.lbfunc (callable) –
- An alternative function to be used instead of the default in calculating Lorentzian broadening, which receives the following:
df: the dataframeself.df1containing the quantities used for calculating the spectrumpressure_atm:self.pressurein units of atmospheric pressure (1.01325 bar)mole_fraction:self.input.mole_fraction, the mole fraction of the species for which the spectrum is being calculatedTgas:self.input.Tgas, gas temperature in KTref:self.input.Tref, reference temperature for calculations in Kdiluent:self._diluent, the dictionary of diluents giving the mole fraction of eachdiluent_broadening_coeff: a dictionary of the broadening coefficients for each diluentisneutral: When calculating the spectrum of an atomic species, whether or not it is neutral (alwaysNonefor molecules)
- Returns:
gamma_lb,shift- The total Lorentzian HWHM [\(cm^{-1}\)], and the shift [\(cm^{-1}\)] to be subtracted from the wavenumber array to account for lineshift. If setting the lineshift here is not desired, the 2nd return object can be anything for whichbool(shift)==FalselikeNone. gamma_lb must be array-like but can also be a vaex expression if the dataframe type is vaex.
If unspecified, the broadening is handled by default by
gamma_vald3()for atoms when using the Kurucz databank, andpressure_broadening_HWHM()for molecules.For the NIST databank, the
lbfuncparameter is compulsory as NIST doesn’t provide broadening parameters.pfsource (
string) – The source for the partition function tables for an interpolator or energy level tables for a calculator. Sources implemented so far are ‘barklem’ and ‘kurucz’ for the former, and ‘nist’ for the latter. ‘default’ is currently ‘nist’. Thepfsourcecan be changed post-initialisation using theset_atomic_partition_functions()method. See the provided example for more details.potential_lowering (float (cm-1/Zeff**2)) – The value of potential lowering, only relevant when
pfsourceis ‘kurucz’ as it depends on both temperature and potential lowering. Can be changed on the fly by settingsf.input.potential_lowering. Allowed values are typically: -500, -1000, -2000, -4000, -8000, -16000, -32000. Again, see the provided example for more details.
Examples
An example using
SpectrumFactory,load_databank(), theSpectrummethods, andunitsfrom radis import SpectrumFactory from astropy import units as u sf = SpectrumFactory(wavelength_min=4165 * u.nm, wavelength_max=4200 * u.nm, isotope='1,2', truncation=10, # cm-1 optimization=None, medium='vacuum', verbose=1, # more for more details ) sf.load_databank('HITRAN-CO2-TEST') # predefined in ~/radis.json s = sf.eq_spectrum(Tgas=300 * u.K, path_length=1 * u.cm) s.rescale_path_length(0.01) # cm s.plot('radiance_noslit', Iunit='µW/cm2/sr/nm')
Refer to the online Examples for more cases.
Examples using
radis.SpectrumFactory¶
Performance increase of broadening_methods and LDM optimizations.
Performance increase of broadening_methods and LDM optimizations.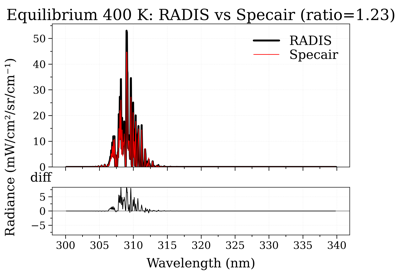
Compare OH(A-X) electronic spectra: RADIS vs Specair
Compare OH(A-X) electronic spectra: RADIS vs Specair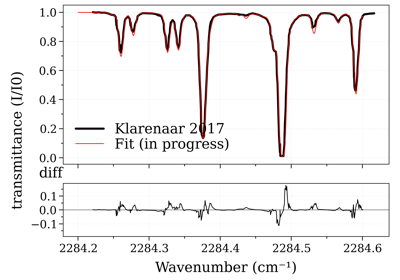
Legacy #2: non-equilibrium CO2 (Tvib_12, Tvib_3, Trot)
Legacy #2: non-equilibrium CO2 (Tvib_12, Tvib_3, Trot)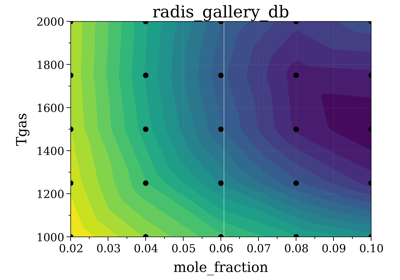
Example #7: Database fitting using SpecDatabase.fit_spectrum
Example #7: Database fitting using SpecDatabase.fit_spectrumNotes
High-level wrapper to SpectrumFactory:
Main Methods:
For advanced use:
Inputs and parameters can be accessed a posteriori with :
input: physical inputparams: computational parametersmisc: miscellaneous parameters (don’t change output)
References
See also
- df0[source]¶
initial line database after loading. If for any reason, you want to manipulate the line database manually (for instance, keeping only lines emitting by a particular level), you need to access the
df0attribute ofSpectrumFactory.Warning
never overwrite the
df0attribute, else some metadata may be lost in the process. Only use inplace operations. If reducing the number of lines, add a df0.reset_index()For instance:
from radis import SpectrumFactory sf = SpectrumFactory( wavenum_min= 2150.4, wavenum_max=2151.4, pressure=1, isotope=1) sf.load_databank('HITRAN-CO-TEST') sf.df0.drop(sf.df0[sf.df0.vu!=1].index, inplace=True) # keep lines emitted by v'=1 only sf.eq_spectrum(Tgas=3000, name='vu=1').plot()
df0contains the lines as they are loaded from the database.df1is generated during the spectrum calculation, after the line database reduction steps, population calculation, and scaling of intensity and broadening parameters with the calculated conditions.See also
df1- Type:
pd.DataFrame
- df1[source]¶
line database, scaled with populations + linestrength cutoff Never edit manually. See all comments about
df0See also
df0- Type:
pd.DataFrame
- eq_spectrum(Tgas, mole_fraction=None, path_length=None, diluent=None, pressure=None, name=None) Spectrum[source]¶
Generate a spectrum at equilibrium.
- Parameters:
Tgas (float or
Quantity) – Gas temperature (K)mole_fraction (float) – database species mole fraction. If None, Factory mole fraction is used.
diluent (str or dictionary) – can be a string of a single diluent or a dictionary containing diluent name as key and its mole_fraction as value
path_length (float or
Quantity) – slab size (cm). IfNone, the default Factorypath_lengthis used.pressure (float or
Quantity) – pressure (bar). IfNone, the default Factorypressureis used.name (str) – output Spectrum name (useful in batch)
- Returns:
s –
Returns a
Spectrumobject- Return type:
Examples
- ::
from radis import SpectrumFactory sf = SpectrumFactory( wavenum_min=2900, wavenum_max=3200, molecule=”OH”, wstep=0.1, ) sf.fetch_databank(“hitemp”)
s1 = sf.eq_spectrum(Tgas=300, path_length=1, pressure=0.1) s2 = sf.eq_spectrum(Tgas=500, path_length=1, pressure=0.1)
References
See also
- eq_spectrum_gpu(Tgas, mole_fraction=None, diluent=None, path_length=None, pressure=None, name=None, backend='vulkan', device_id=0, exit_gpu=False, verbose=None) Spectrum[source]¶
Generate a spectrum at equilibrium with calculation of lineshapes and broadening done on the GPU.
- Parameters:
Tgas (float or
Quantity) – Gas temperature (K)mole_fraction (float) – database species mole fraction. If None, Factory mole fraction is used.
path_length (float or
Quantity) – slab size (cm). IfNone, the default Factorypath_lengthis used.pressure (float or
Quantity) – pressure (bar). IfNone, the default Factorypressureis used.name (str) – output Spectrum name (useful in batch)
- Other Parameters:
device_id (int, str) – Select the GPU device. If
int, specifies the device index, which is printed for convenience during GPU initialization with backend=’vulkan’ (default). Ifstr, return the first device that includes the specified string (case-insensitive). If not found, return the device at index 0. default = 0exit_gpu (bool) – Specifies whether the GPU app should be exited after producing the spectrum. Usually this is undesirable, because the GPU computations start to benefit after the first spectrum is produced by calling s.recalc_gpu(). See also
recalc_gpu()default = Falsebackend (str) – Since version 0.16, only
'vulkan'backend is supported. In previous versions,'gpu-cuda'and'cpu-cuda'were available to switch to a CUDA backend, but this has been deprecated in favor of the Vulkan backend... warning:: – The
backendparameter is deprecated. Only the Vulkan backend is supported.
- Returns:
s – Returns a
SpectrumobjectUse the
get()method to get something among['radiance', 'radiance_noslit', 'absorbance', etc...]Or directly the
plot()method to plot it. See [1]_ to get an overview of all Spectrum methods- Return type:
Examples
Examples using
radis.lbl.SpectrumFactory.eq_spectrum_gpu¶See also
- eq_spectrum_gpu_interactive(var='transmittance', slit_function=0.0, mpl_backend='', plotkwargs={}, *vargs, **kwargs) Spectrum[source]¶
- Parameters:
var (TYPE, optional) – DESCRIPTION. The default is “transmittance”.
slit_function (TYPE, optional) – DESCRIPTION. The default is 0.0.
*vargs (TYPE) – arguments forwarded to
eq_spectrum_gpu()**kwargs (dict) – arguments forwarded to
eq_spectrum_gpu()In particular, seebackend=.plotkwargs (dict) – arguments forwarded to
plot()
- Returns:
s – DESCRIPTION.
- Return type:
TYPE
Examples
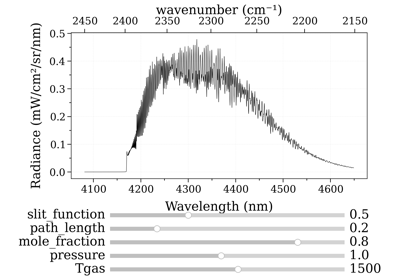
from radis import SpectrumFactory from radis.tools.plot_tools import ParamRange sf = SpectrumFactory(2200, 2400, # cm-1 molecule='CO2', isotope='1,2,3', wstep=0.002, ) sf.fetch_databank('hitemp') s = sf.eq_spectrum_gpu_interactive(Tgas=ParamRange(300.0,2000.0,1200.0), #K pressure=0.2, #bar mole_fraction=0.1, path_length=ParamRange(0,10,2.0), #cm slit_function=ParamRange(0,1,0), #cm )
- fit_legacy(s_exp, model, fit_parameters, bounds={}, plot=False, solver_options={'maxiter': 300}, **kwargs) Spectrum | OptimizeResult[source]¶
Fit an experimental spectrum with an arbitrary model and an arbitrary number of fit parameters. This method calls
fit_legacy()which is still functional. However, we recommend usingfit_spectrum().- Parameters:
s_exp (Spectrum) – experimental spectrum. Should have only spectral array only. Use
take(), e.g:sf.fit_legacy(s_exp.take('transmittance'))
model (func -> Spectrum) – a line-of-sight model returning a Spectrum. Example :
Tvib12Tvib3Trot_NonLTEModel()fit_parameters (dict) –
example:
{fit_parameter:initial_value}
bounds (dict, optional) –
example:
{fit_parameter:[min, max]}
fixed_parameters (dict) –
fixed parameters given to the model. Example:
fit_spectrum(fixed_parameters={"vib_distribution":"treanor"})
- Other Parameters:
plot (bool) – if
True, plot spectra as they are computed; and plot the convergence of the residual. DefaultFalsesolver_options (dict) – parameters forwarded to the solver. More info in
minimizeExample:{"maxiter": (int) max number of iteration default ``300``, }kwargs (dict) – forwarded to
fit_spectrum()
- Returns:
s_best (Spectrum) – best spectrum
res (OptimizeResults) – output of
minimize
Examples
See a one-temperature fit example and a non-LTE fit example
More advanced tools for interactive fitting of multi-dimensional, multi-slabs spectra can be found in
fitroom.See also
fit_spectrum(),Tvib12Tvib3Trot_NonLTEModel(),fitroom
- generate_perf_profile()[source]¶
Generate a visual/interactive performance profile diagram for the last calculated spectrum, with
tuna.Requires a
profilerkey with in Spectrum.conditions, andtunainstalled.Note
print_perf_profile()is an ascii-version which does not requiretuna.Examples
sf = SpectrumFactory(...) sf.eq_spectrum(...) sf.generate_perf_profile()
See typical output in https://github.com/radis/radis/pull/325
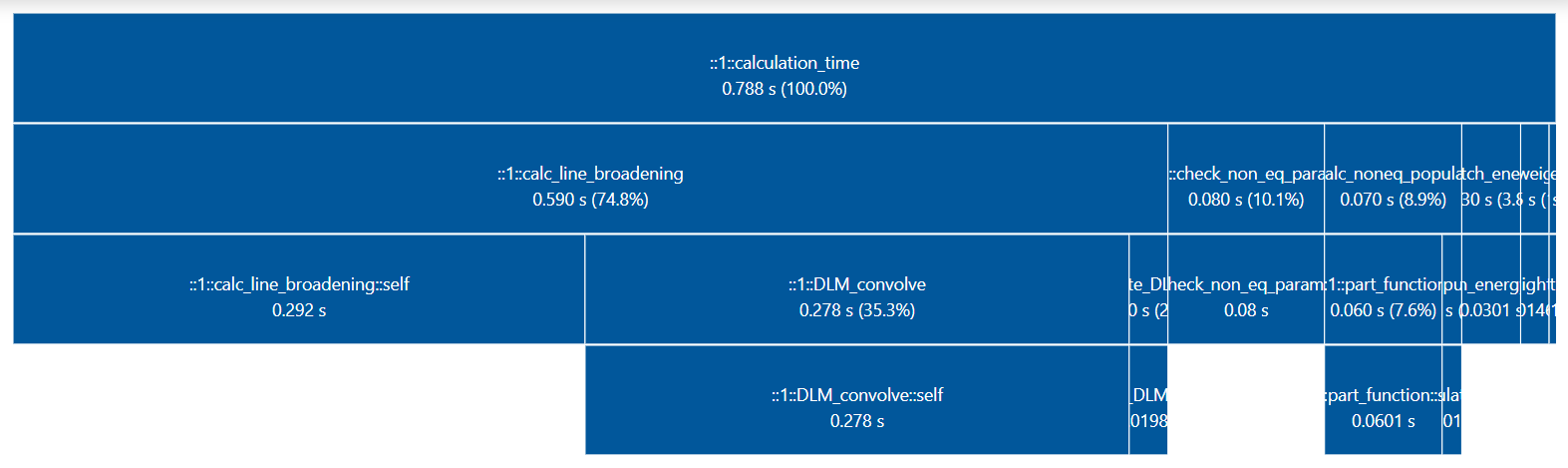
Note
You can also profile with
tunadirectly:python -m cProfile -o program.prof your_radis_script.py tuna your_radis_script.py
See also
- misc[source]¶
Miscellaneous parameters (
MiscParams) params that cannot change the output of calculations (ex: number of CPU, etc.)
- molparam[source]¶
contains information about molar mass; isotopic abundance.
See
MolParams- Type:
MolParam
- non_eq_spectrum(Tvib=None, Trot=None, Ttrans=None, Telec=None, mole_fraction=None, path_length=None, diluent=None, pressure=None, vib_distribution='boltzmann', rot_distribution='boltzmann', overpopulation=None, name=None) Spectrum[source]¶
Calculate emission spectrum in non-equilibrium case. Calculates absorption with broadened linestrength and emission with broadened Einstein coefficient.
- Parameters:
Tvib (float) – vibrational temperature [K] can be a tuple of float for the special case of more-than-diatomic molecules (e.g: CO2); only applicable for molecules, not atoms
Trot (float) – rotational temperature [K]; only applicable for molecules, not atoms
Ttrans (float) – translational temperature [K]. If None, translational temperature is taken as rotational temperature (valid at 1 atm for times above ~ 2ns which is the RT characteristic time)
Telec (float) – electronic temperature [K]. For molecules, see
ElectronicSpectraWarningmole_fraction (float) – database species mole fraction. If None, Factory mole fraction is used.
diluent (str or dictionary) – can be a string of a single diluent or a dictionary containing diluent name as key and its mole_fraction as value
path_length (float or
Quantity) – slab size (cm). IfNone, the default Factorypath_lengthis used.pressure (float or
Quantity) – pressure (bar). IfNone, the default Factorypressureis used.
- Other Parameters:
vib_distribution (
'boltzmann','treanor') – vibrational distributionrot_distribution (
'boltzmann') – rotational distributionoverpopulation (dict, or
None) –add overpopulation factors for given levels:
{level:overpopulation_factor}
name (str) – output Spectrum name (useful in batch)
- Returns:
s –
Returns a
Spectrumobject- Return type:
Examples
from radis import SpectrumFactory sf = SpectrumFactory( wavenum_min=2000, wavenum_max=3000, molecule="CO", isotope="1,2,3", wstep="auto" ) sf.fetch_databank("hitemp", load_columns='noneq') s1 = sf.non_eq_spectrum(Tvib=2000, Trot=600, path_length=1, pressure=0.1) s2 = sf.non_eq_spectrum(Tvib=2000, Trot=600, path_length=1, pressure=0.1)
Multi-vibrational temperature. Below we compare non-LTE spectra of CO2 where all vibrational temperatures are equal, or where the bending and symmetric modes are in equilibrium with rotation
from radis import SpectrumFactory sf = SpectrumFactory( wavenum_min=2000, wavenum_max=3000, molecule="CO2", isotope="1,2,3", ) sf.fetch_databank("hitemp", load_columns='noneq') # nonequilibrium between bending+symmetric and asymmetric modes : s1 = sf.non_eq_spectrum(Tvib=(600, 600, 2000), Trot=600, path_length=1, pressure=1) # all vibrational temperatures are equal : s2 = sf.non_eq_spectrum(Tvib=(2000, 2000, 2000), Trot=600, path_length=1, pressure=1)
References
See also
- optically_thin_power(Tgas=None, Tvib=None, Trot=None, Ttrans=None, vib_distribution='boltzmann', rot_distribution='boltzmann', mole_fraction=None, path_length=None, unit='mW/cm2/sr')[source]¶
Calculate total power emitted in equilibrium or non-equilibrium case in the optically thin approximation: it sums all emission integral over the total spectral range.
Warning
this is a fast implementation that doesnt take into account the contribution of lines outside the given spectral range. It is valid for spectral ranges surrounded by no lines, and spectral ranges much broadened than the typical line broadening (~ 1-10 cm-1 in the infrared)
If what you’re looking for is an accurate simulation on a narrow spectral range you better calculate the spectrum (that does take all of that into account) and integrate it with
get_power()- Parameters:
Tgas (float) – equilibrium temperature [K] If doing a non equilibrium case it should be None. Use Ttrans for translational temperature
Tvib (float) – vibrational temperature [K]
Trot (float) – rotational temperature [K]
Ttrans (float) – translational temperature [K]. If None, translational temperature is taken as rotational temperature (valid at 1 atm for times above ~ 2ns which is the RT characteristic time)
mole_fraction (float) – database species mole fraction. If None, Factory mole fraction is used.
path_length (float) – slab size (cm). If None, Factory mole fraction is used.
unit (str) – output unit. Default
'mW/cm2/sr'
- Returns:
float – see
unit=.- Return type:
Returns total power density in mW/cm2/sr (unless different unit is chosen),
See also
- params[source]¶
Parametersthey may change the output of calculations (ex: threshold, cutoff, broadening methods, etc.)- Type:
Computational parameters
- predict_time()[source]¶
predict_time(self) uses the input parameters like Spectral Range, Number of lines, wstep, truncation to predict the estimated calculation time for the Spectrum broadening step(bottleneck step) for the current optimization and broadening_method. The formula for predicting time is based on benchmarks performed on various parameters for different optimization, broadening_method and deriving its time complexity.
Benchmarks: https://anandxkumar.github.io/Benchmark_Visualization_GSoC_2021/
Complexity vs Calculation Time Visualizations LBL>Voigt: LINK, DIT>Voigt: LINK, DIT>FFT: LINK
- Returns:
float
- Return type:
Predicted time in seconds.
- print_perf_profile(number_format='{:.3f}', precision=16)[source]¶
Prints Profiler output dictionary in a structured manner for the last calculated spectrum
Examples
sf.print_perf_profile() # output >> spectrum_calculation 0.189s ████████████████ check_line_databank 0.000s check_non_eq_param 0.042s ███ fetch_energy_5 0.015s █ calc_weight_trans 0.008s reinitialize 0.002s copy_database 0.000s memory_usage_warning 0.002s reset_population 0.000s calc_noneq_population 0.041s ███ part_function 0.035s ██ population 0.006s scaled_non_eq_linestrength 0.005s map_part_func 0.001s corrected_population_se 0.003s calc_emission_integral 0.006s applied_linestrength_cutoff 0.002s calc_lineshift 0.001s calc_hwhm 0.007s generate_wavenumber_arrays 0.001s calc_line_broadening 0.074s ██████ precompute_LDM_lineshapes 0.012s LDM_Initialized_vectors 0.000s LDM_closest_matching_line 0.001s LDM_Distribute_lines 0.001s LDM_convolve 0.060s █████ others 0.001s calc_other_spectral_quan 0.003s generate_spectrum_obj 0.000s others -0.016s- Other Parameters:
precision (int, optional) – total number of blocks. Default 16.
See also