






radis.tools package¶
Submodules¶
- radis.tools.code_profiler module
- radis.tools.database module
- radis.tools.fitting module
- radis.tools.gascomp module
- radis.tools.line_survey module
- radis.tools.new_fitting module
- radis.tools.plot_tools module
- radis.tools.read_wav_index module
- radis.tools.slit module
- radis.tools.track_ref module
Module contents¶
Tools : database of spectra, line survey.
- class SpecDatabase(path='.', filt='.spec', add_info=None, add_date='%Y%m%d', verbose=True, binary=True, nJobs=-2, batch_size='auto', lazy_loading=True, update_register_only=False)[source]¶
Bases:
SpecListA Spectrum Database class to manage them all.
It basically manages a list of Spectrum JSON files, adding a Pandas dataframe structure on top to serve as an efficient index to visualize the spectra input conditions, and slice through the Dataframe with easy queries
Similar to
SpecList, but associated and synchronized with a folder- Parameters:
path (str) – a folder to initialize the database
filt (str) – only consider files ending with
filt. Default.specbinary (boolean) – if
True, open Spectrum files as binary files. IfFalseand it fails, try as binary file anyway. DefaultFalse.lazy_loading (bool``) – If
True, load only the data from the summary csv file and the spectra will be loaded when accessed by the get functions. IfFalse, load all the spectrum files. IfTrueand the summary .csv file does not exist, load all spectra
- Other Parameters:
Input for :class:`~joblib.parallel.Parallel` loading of database
nJobs (int) – Number of processors to use to load a database (useful for big databases). BE CAREFULL, no check is done on processor use prior to the execution ! Default
-2: use all but 1 processors. Use1for single processor.batch_size (int or
'auto') – The number of atomic tasks to dispatch at once to each worker. When individual evaluations are very fast, dispatching calls to workers can be slower than sequential computation because of the overhead. Batching fast computations together can mitigate this. Default:'auto'More information in :class:`joblib.parallel.Parallel`
Examples
>>> db = SpecDatabase(r"path/to/database") # create or loads database >>> db.update() # in case something changed >>> db.see(['Tvib', 'Trot']) # nice print in console >>> s = db.get('Tvib==3000')[0] # get a Spectrum back >>> db.add(s) # update database (and raise error because duplicate!)
Note that
SpectrumFactorycan be configured to automatically look-up and update a database when spectra are calculated.The function to auto retrieve a Spectrum from database on calculation time is a method of DatabankLoader class
You can see more examples on the Spectrum Database section of the website.
See also
load_spec(),store(),Methods,get(),get_closest(),get_unique(),Methods,see(),update(),add(),compress_to(),find_duplicates(),Compare,fit_spectrum()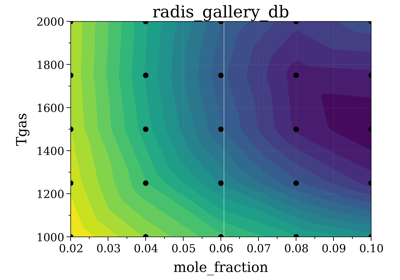
Example #7: Database fitting using SpecDatabase.fit_spectrum
Example #7: Database fitting using SpecDatabase.fit_spectrum- add(spectrum: Spectrum, store_name=None, if_exists_then='increment', **kwargs)[source]¶
Add Spectrum to database, whether it’s a
Spectrumobject or a file that stores one. Check it’s not in database already.- Parameters:
spectrum (
Spectrumobject, or path to a .spec file (str)) – if aSpectrumobject: stores it in the database (using thestore()method), then adds the file to the database folder. if a path to a file (str): first copy the file to the database folder, then loads the copied file to the database.- Other Parameters:
store_name (
str, orNone) – name of the file where the spectrum will be stored. IfNone, name is generated automatically from the Spectrum conditions (seeadd_info=andif_exists_then=)if_exists_then (
'increment','replace','error','ignore') – what to do if file already exists. If'increment'an incremental digit is added. If'replace'file is replaced (!). If'ignore'the Spectrum is not added to the database and no file is created. If'error'(or anything else) an error is raised. Default'increment'.**kwargs (**dict) – extra parameters used in the case where spectrum is a file and a .spec object has to be created (useless if
spectrumis a file already). kwargs are forwarded to Spectrum.store() method. See thestore()method for more information.Note
Other
store()parameters can be given as kwargs arguments. See below :compress (0, 1, 2) – if
Trueor 1, save the spectrum in a compressed formif 2, removes all quantities that can be regenerated with
update(), e.g, transmittance if abscoeff and path length are given, radiance if emisscoeff and abscoeff are given in non-optically thin case, etc. If not given, use the value ofSpecDatabase.binaryThe performances are usually better if compress = 2. See https://github.com/radis/radis/issues/84.add_info (list) – append these parameters and their values if they are in conditions example:
nameafter = ['Tvib', 'Trot']
discard (list of str) – parameters to exclude. To save some memory for instance Default
['lines', 'populations']: retrieved Spectrum will loose theline_survey()andplot_populations()methods (but it saves a ton of memory!).
Examples
from radis.tools import SpecDatabase db = SpecDatabase(r"path/to/database") # create or loads database db.add(s, discard=['populations'])
You can see more examples on the Spectrum Database section of the website.
See also
- compress_to(new_folder, compress=True, if_exists_then='error')[source]¶
Saves the Database in a new folder with all Spectrum objects under compressed (binary) format. Read/write is much faster. After the operation, a new database should be initialized in the new_folder to access the new Spectrum.
- Parameters:
new_folder (str) – folder where to store the compressed SpecDatabase. If doesn’t exist, it is created.
compress (boolean, or 2) – if
True, saves under binary format. Faster and takes less space. If2, additionally remove all redundant quantities.if_exists_then (
'increment','replace','error','ignore') – what to do if file already exists. If'increment'an incremental digit is added. If'replace'file is replaced (!). If'ignore'the Spectrum is not added to the database and no file is created. If'error'(or anything else) an error is raised. Default'error'.
See also
- find_duplicates(columns=None)[source]¶
Find spectra with same conditions. The first duplicated spectrum will be
'False', the following will be'True'(see .duplicated()).- Parameters:
columns (list, or
None) – columns to find duplicates on. IfNone, use all conditions.
Examples
db.find_duplicates(columns={'x_e', 'x_N_II'}) Out[34]: file 20180710_101.spec True 20180710_103.spec True dtype: bool
You can see more examples in the Spectrum Database section
- fit_spectrum(s_exp, residual=None, var=None, normalize=False, normalize_how='max', plot=False, conditions='', **kwconditions)[source]¶
Returns the Spectrum in the database that has the lowest residual with
s_exp.- Parameters:
s_exp (Spectrum) –
Spectrumto fit (typically: experimental spectrum)- Other Parameters:
var (str) – spectral variable to compare (e.g., ‘radiance’, ‘absorbance’). Required if
s_exphas multiple variables andresidualis not provided.plot (bool) – if
True, plot the residuals against the varying conditions. If one condition varies, a 1D plot is generated. If two conditions vary, a 2D contour plot is generated usingplot_cond(). DefaultFalse.conditions, **kwconditions (str, **dict) – restrain fitting to only Spectrum that match the given conditions in the database. See
get()for more information.normalize (bool, or Tuple) – see
get_residual()normalize_how (‘max’, ‘area’) – see
get_residual()
- Returns:
s_best – closest Spectrum to
s_exp- Return type:
Examples
Compare an experimental spectrum to a database of precomputed spectra:
from radis.tools import SpecDatabase db = SpecDatabase('path/to/database') s_best = db.fit_spectrum(s_exp, plot=True) s_best.plot(nfig='same')
Example #7: Database fitting using SpecDatabase.fit_spectrum
Example #7: Database fitting using SpecDatabase.fit_spectrumUsing a customized residual function (below: to get the transmittance):
from radis import get_residual db = SpecDatabase('...') db.fit_spectrum(s_exp, residual=lambda s_exp, s: get_residual(s_exp, s, var='transmittance'))
You can see more examples on the Spectrum Database section More advanced tools for interactive fitting of multi-dimensional, multi-slabs spectra can be found in
fitroom.See also
- interpolate(**kwconditions)[source]¶
Interpolate existing spectra from the database to generate a new spectrum with conditions kwargs
Examples
db.interpolate(Tgas=300, mole_fraction=0.3)
- to_dict()[source]¶
Returns all Spectra in database under a dictionary, indexed by file.
- Returns:
out – {path : Spectrum object} dictionary
- Return type:
dict
Note
SpecList.items().values()is equivalent toSpecList.get()
- update(force_reload=False, filt='.spec', update_register_only=False)[source]¶
Reloads database, updates internal index structure and export it in
<database>.csv.- Parameters:
force_reload (boolean) – if
True, reloads files already in database. DefaultFalsefilt (str) – only consider files ending with
filt. Default.spec
- Other Parameters:
update_register_only (bool) – if
True, load files and update csv but do not keep the Spectrum in memory. DefaultFalse
Notes
Can be loaded in parallel using joblib by setting the
nJobsandbatch_sizeattributes ofSpecDatabase. Seejoblib.parallel.Parallelfor information on the arguments
- get_FWHM(w, I, return_index=False)[source]¶
Calculate full width half maximum (FWHM) by comparing amplitudes
- Parameters:
w, I (arrays)
return_index (boolean) – if True, returns indexes for half width boundaries. Default
False
- Returns:
FWHM (float) – full width at half maximum
[xmin, xmax] (int)
- get_effective_FWHM(w, I)[source]¶
Calculate full-width-at-half-maximum (FWHM) of a triangular slit of same area and height 1
- Parameters:
w, I (arrays)
- Returns:
fwhm – effective FWHM
- Return type:
float
- get_eq_mole_fraction(initial_mixture, T_K, p_Pa)[source]¶
Calculates chemical equilibrium mole fraction at temperature T, using the CANTERA
equilibrate()function.The calculation uses the default GRI3.0 mechanism, which was designed to model natural gas combustion, including NO formation and reburn chemistry. See GRI 3.0.
When using, cite the [CANTERA] package.
- Parameters:
initial_mixture (str) –
Gas composition. Example:
'N2:0.79, O2:0.21, CO2:363e-6'Or:
'CO2:1'T_K (float (K)) – temperature (Kelvin) to calculate equilibrium
P_Pa (float (Pa)) – temperature (Pascal) to calculate equilibrium
Examples
Calculate equilibrium mixture of CO2 at 2000 K, 1 atm:
get_eq_mole_fraction('CO2:1', 2000, 101325) >>> {'C': 1.7833953335281855e-19, 'CO': 0.01495998583472384, 'CO2': 0.9775311634424326, 'O': 5.7715610124613225e-05, 'O2': 0.007451135112719029}
References
- load_spec(file, binary=True) Spectrum[source]¶
Loads a .spec file into a
Spectrumobject. Addsfilein the Spectrumfileattribute.- Parameters:
file (str) – .spec file to load
binary (boolean) – set to
Trueif the file is encoded as binary. DefaultTrue. Will autodetect if it fails, but that may take longer.
- Returns:
Spectrum
- Return type:
a
Spectrumobject
Examples
Example #3: non-equilibrium spectrum (Tvib, Trot, x_CO)
Example #3: non-equilibrium spectrum (Tvib, Trot, x_CO)See also

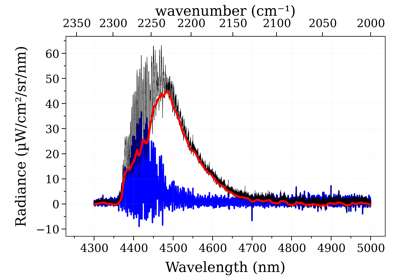
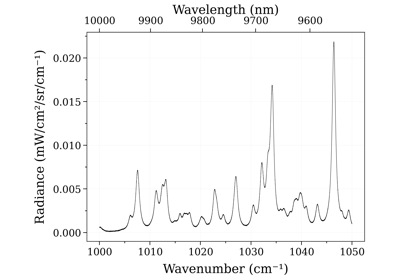
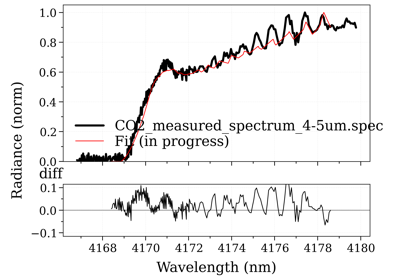
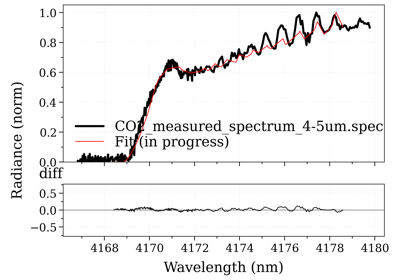
- plot_slit(w, I=None, wunit='', plot_unit='same', Iunit=None, warnings=True, ls='-', title=None, waveunit=None)[source]¶
Plot slit, calculate and display FWHM, and calculate effective FWHM. FWHM is calculated from the limits of the range above the half width, while FWHM is the equivalent width of a triangular slit with the same area
- Parameters:
w, I (arrays or (str, None)) – if str, open file directly
waveunit (
'nm','cm-1'or'') – unit of input wplot_unit (
'nm','cm-1'or'same') – change plot unit (and FWHM units)Iunit (str, or None) – give Iunit
warnings (boolean) – if True, test if slit is correctly centered and output a warning if it is not. Default
True
- Returns:
fix, ax – figure and ax
- Return type:
matplotlib objects
Examples
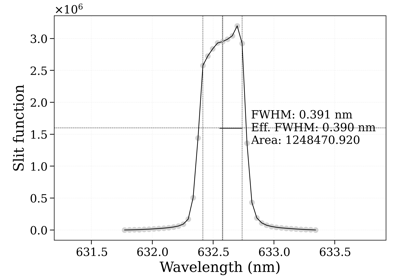
- plot_spec(file, what='radiance', title=True, **kwargs)[source]¶
Plot a .spec file. Uses the
plot()method internally.- Parameters:
file (str, or Spectrum object) – .spec file to load, or Spectrum object directly
- Other Parameters:
kwargs (dict) – arguments forwarded to
plot()- Returns:
fig – where the Spectrum has been plotted
- Return type:
matplotlib figure
See also
- save(s: Spectrum, path, discard=[], compress=True, add_info=None, add_date=None, if_exists_then='increment', verbose=True, warnings=True)[source]¶
Save a
Spectrumobject in JSON format. Object can be recovered withload_spec(). If manySpectrumare saved in a same folder you can view their properties with theSpecDatabasestructure.- Parameters:
s (Spectrum) – to save
path (str or file-like object) – If a string: filename to save. No extension needed. If filename already exists then a digit is added. If filename is a directory then a new file is created within this directory.
If a file-like object (e.g.,
io.BytesIO,io.StringIO): writes directly to the object without any file system operations. UseBytesIOwhencompress=True(binary output), useStringIOwhencompress=False(text output). When using file-like objects, theadd_date,add_info, andif_exists_thenparameters are ignored.discard (list of str) – parameters to discard. To save some memory.
compress (boolean) – if
False, save under text format, readable with any editor. ifTrue, saves under binary format. Faster and takes less space. If2, removes all quantities that can be regenerated with s.update(), e.g, transmittance if abscoeff and path length are given, radiance if emisscoeff and abscoeff are given in non-optically thin case, etc. DefaultFalseadd_info (list, or None/False) – append these parameters and their values if they are in conditions. e.g:
add_info = ['Tvib', 'Trot']
add_date (str, or
None/False) – adds date in strftime format to the beginning of the filename. e.g:add_date = '%Y%m%d'
if_exists_then (
'increment','replace','error','ignore') – what to do if file already exists. If'increment'an incremental digit is added. If'replace'file is replaced (!). If'ignore'the Spectrum is not added to the database and no file is created. If'error'(or anything else) an error is raised. Default'increment'.
- Returns:
fout – If path was a string: filename used (may be different from given path as new info or incremental identifiers are added). If path was a file-like object: returns the same object.
- Return type:
str or file-like object
See also